|
Foreign Keys |




|
|
Foreign Keys |
|
In the context of relational databases, a foreign key is a referential constraint between two tables. The foreign key identifies a column or a set of columns in one (referencing) table, that refers to a set of columns in another (referenced) table. The columns in the referencing table must be the primary key or other candidate key in the referenced table. The values in one row of the referencing columns must occur in a single row in the referenced table. Thus, a row in the referencing table cannot contain values that do not exist in the referenced table (except potentially NULL). This way, references can be made to link information together and it is an essential part of database normalization. Multiple rows in the referencing table may refer to the same row in the referenced table. Most of the time, it reflects the one (master table, or referenced table) to many (child table, or referencing table) relationship.
For example, the Emp and Hist tables, that are part of the emp.mdb sample database, will be used.
Note:
| • | emp.mdb can be found in the C:\Users\Public\Documents\Ecrion\Data Aggregation Server 2013\Samples\Database Samples folder. |

The ID column in the Emp table is a primary key and, as it can be noticed, is referenced in the Hist table. This means that the ID column in the Hist table is a foreign key.
To set a foreign key in Data Architect, the user must right click on the table containing the column to be set as foreign key (in this example, the Hist table) and select Edit Data Source.
As a result, the following dialog will be displayed.
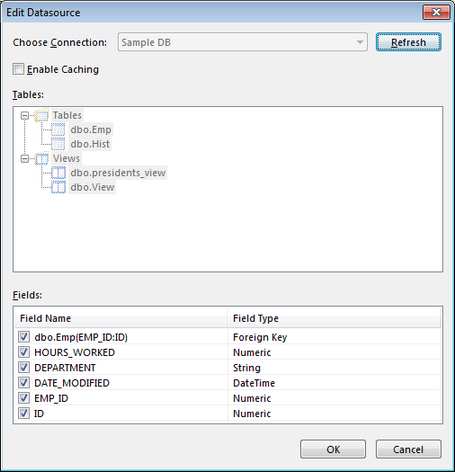
The checkbox corresponding to the Emp(EMP_ID:ID) field must be selected, in order to set it as foreign key.
After selecting the OK button, a link representing the relationship between the two tables will be added.
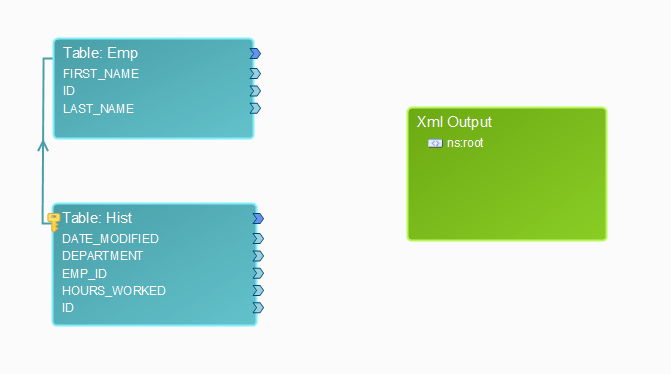
In Data Architect, the relationship that was created by setting the foreign key acts like an INNER JOIN. This operation creates a new result table, by combining every record from Emp table with every record from Hist table, based upon the join-predicate (Emp.ID=Hist.ID).
For a better overview of the result, the fields from the two input tables must be connected to the output, as follows:
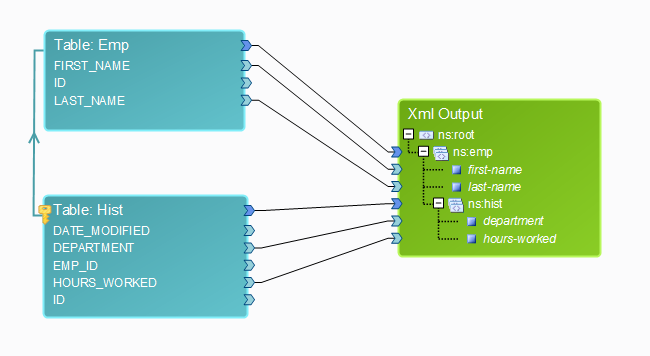
Output:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<ns:root xmlns:ns="http://www.tempuri.org/XML">
<ns:emp first-name="John" last-name="Brown">
<ns:hist department="Accounting" hours-worked="300"/>
<ns:hist department="Sales" hours-worked="500"/>
<ns:hist department="Development" hours-worked="3000"/>
<ns:hist department="Accounting" hours-worked="100"/>
</ns:emp>
<ns:emp first-name="Mary" last-name="Jane">
<ns:hist department="Accounting" hours-worked="1000"/>
<ns:hist department="Sales" hours-worked="8000"/>
<ns:hist department="Development" hours-worked="5000"/>
</ns:emp>
<ns:emp first-name="Arthur" last-name="Clark"/>
</ns:root>
For every employee ID in the Emp table, the following columns were selected:
| • | FIRST_NAME from the Emp table; |
| • | LAST_NAME from the Emp table; |
| • | DEPARTMENT from the Hist table; |
| • | HOURS_WORKED from the Hist table. |